分布式-服务治理(下)
分布式-服务治理(下)
xiaoyan监控系统
监控中心的作用
建立完善的监控体系是确保系统稳定性和性能优化的关键。监控中心的主要作用包括:
- 数据可视化:通过可视化工具直观展示系统的运行状态、资源使用情况等关键指标,帮助运维人员快速了解系统健康状况。
- 长期趋势预测:通过对监控数据的持续收集和统计分析,预测系统指标的发展趋势,例如通过磁盘使用率的趋势分析,提前规划资源扩容,避免资源瓶颈。
- 故障预警与告警:当系统指标出现异常时,及时通知管理员,以便迅速采取措施处理故障,确保业务的连续性和稳定性。
常见监控对象与指标
- 硬件监控:CPU状态、磁盘状态、电源状态、内存状态、宽带状态、机器温度等
- 服务器监控:CPU、内存、磁盘、网络
- 数据库监控:数据库连接数量、QPS(每秒查询次数)、TPS(每秒事务处理次数)、缓存命中率、主从延时、慢查询、锁状态等
- 中间件监控:
- Nginx:活跃连接数、等待连接数、抛弃连接数、请求量、耗时、错误率
- Tomcat:最大线程数、当前线程数、请求量、耗时、堆内存使用情况、GC次数和耗时
- 缓存:成功连接数、阻塞连接数、已使用内存、缓存命中率、内存碎片率、请求量、耗时
- 详细队列:连接数、队列数、生产速率、消费速率、消息堆积量
- 应用监控:
- Http接口:URL存活、请求量、耗时、异常量
- RPC接口:请求量、耗时、超时量、拒绝量
- JVM:内存各分区大小、GC次数、GC耗时、当前线程数、线程死锁数
- 线程池:活跃线程数、任务队列大小、任务执行耗时、拒绝任务数
- 连接池:总连接数、活跃连接数
- 日志监控:访问日志、错误日志
监控系统的基本流程
市面上的监控系统虽然在具体实现上有所差异,但其基本流程大致相同,主要包括以下几个关键步骤:
- 数据采集
数据采集是监控系统的基础,其方式多种多样,主要包括:
- 日志埋点采集:通过工具如Filebeat等进行日志的上报和解析,获取系统运行日志中的关键信息。
- JMX标准接口:利用Java Management Extensions (JMX)标准接口,获取Java应用的监控指标。
- REST API:被监控对象提供REST API接口,监控系统通过调用API获取数据,例如Elasticsearch (ES)。
- 系统命令行:通过执行系统命令获取监控数据,如使用
top、vmstat等命令获取系统资源使用情况。 - SDK埋点:通过统一的SDK进行侵入式的埋点和上报,适用于需要高精度监控的场景。
- 数据传输
数据传输是将采集到的数据发送给监控系统的关键步骤,通常采用以下协议和模式:
- TCP/UDP协议:数据通过TCP或UDP协议进行传输,适用于实时性要求较高的场景。
- HTTP协议:数据通过HTTP协议进行传输,适用于需要跨网络传输的场景。
- Push模式:监控系统主动将数据推送到监控中心,适用于数据量较小且实时性要求高的场景。
- Pull模式:监控中心主动从被监控对象拉取数据,适用于数据量较大且实时性要求不高的场景。
- 数据存储
数据存储是监控系统的核心环节,主要用于保存采集到的监控数据,以便后续的分析和展示。常见的存储方式包括:
- 时序数据库:如InfluxDB、Prometheus等,适用于存储时间序列数据,支持高效的时间查询和聚合操作。
- 关系型数据库:如MySQL、PostgreSQL等,适用于存储结构化数据,支持复杂的查询和分析。
- 分布式文件系统:如HDFS、Ceph等,适用于存储大规模的日志数据,支持高吞吐量的读写操作。
- 监控展示
监控展示是将存储的监控数据以图形化方式展示出来,帮助运维人员直观了解系统状态。
- 监控告警
监控告警是监控系统的重要功能,通过预设的阈值和规则,及时通知运维人员处理异常情况。常见的告警方式包括:
- 邮件通知:通过邮件发送告警信息,适用于日常监控和通知。
- 短信通知:通过短信发送告警信息,适用于紧急情况下的快速响应。
- 电话通知:通过电话语音通知,适用于需要立即处理的严重故障。
- Webhook:通过Webhook将告警信息推送到其他系统,如Slack、钉钉等,实现自动化处理。
监控系统技术选型
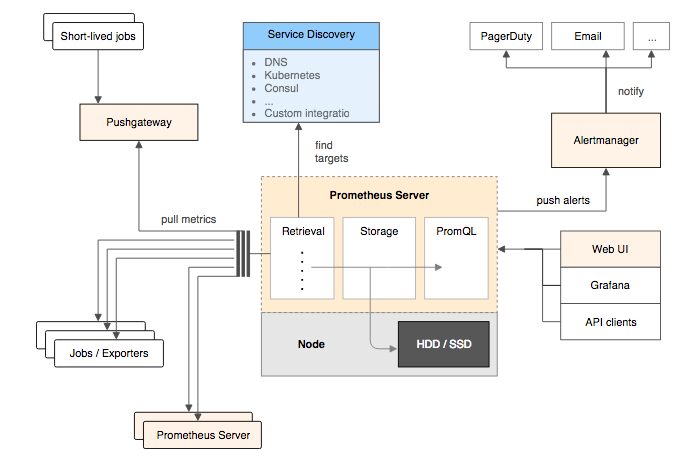
Prometheus是一款由Go语言开发的开源监控和告警工具,以其强大的时序数据库和灵活的查询语言而著称。Prometheus的基本原理是通过HTTP长连接以Pull(监控服务器主动拉取被监控组件数据)的方式进行监控,被监控组件只需提供HTTP接口即可接入监控系统。
Prometheus的特性
- 服务发现机制:Prometheus提供了开箱即用的服务发现机制,能够自动发现监控端点,支持多种服务发现方式,如静态配置、DNS、Kubernetes、Consul等。
- 时序数据库TSDB:Prometheus自研的时序型数据库TSDB(Time Series Database),专门用于存储时间序列数据,支持高效的查询和聚合操作。
- 查询语言PromQL:Prometheus提供了强大的查询语言PromQL(Prometheus Query Language),支持丰富的聚合函数和表达式,能够灵活地进行数据分析和处理。
- 告警规则:Prometheus支持灵活的告警规则配置,包括告警收敛(分组、抑制、静默)、多级路由等高级功能,确保告警的准确性和及时性。
- 生态完善:Prometheus拥有丰富的生态系统,包括各种Exporter、Alertmanager、Grafana等组件,能够满足不同场景的监控需求。
基本架构
- Prometheus Server:核心组件,负责收集、存储监控信息。支持静态配置和动态服务发现,从监控对象获取数据并存储到本地磁盘。Prometheus Server本身也是一个时序型数据库,通过自定义的PromQL对数据进行查询分析。
- Exporter:用于采集数据的组件,负责从被监控对象获取数据并暴露HTTP接口供Prometheus Server拉取。常见的Exporter包括Node Exporter(监控主机)、MySQL Exporter(监控MySQL数据库)等。
- Pushgateway:主要用于瞬时任务的场景,防止Prometheus Server在任务执行完毕前未能及时拉取监控数据。Pushgateway作为数据中转站,接收瞬时任务的监控数据并缓存,供Prometheus Server后续拉取。
日志管理
日志系统
在分布式架构中,日志分散在不同的服务器节点上,传统的日志查看方式需要登录到各个服务器,使用Linux命令逐个排查,效率低下且耗时耗力。为了解决这一问题,集中式日志管理系统应运而生。日志系统本质上是一个集中管理日志的系统,旨在提供高效、便捷的日志采集、处理、存储、展示、查询和告警功能。
一个完善的日志系统应具备以下核心功能:
- 日志采集:支持多种日志格式以及数据源的采集。
- 日志数据清洗/处理:采集到的原始日志数据通常包含噪声和冗余信息,需要进行清洗,去除无效数据和重复数据。对清洗后的日志数据进行进一步处理,如格式转换、字段提取、数据聚合等,以便于后续的存储和分析。
- 存储日志:支持对接多种存储方式,如Elasticsearch(ES)、Hadoop、关系型数据库等,根据日志数据的特点选择合适的存储方案。
- 展示日志:支持可视化展示日志。
- 查询和分析日志:提供友好的查询接口,支持多种条件进行查询和统计分析,以帮助用户快速排除问题。
- 告警:支持内置告警功能,根据预设的规则和阈值,自动触发告警通知。
ELK
ELK是最原始的日志系统架构,由三个项目的首字母组成,即Elasticsearch、Logstash和Kibana。随着技术的发展,ELK架构也在不断演进,引入了新的组件以提升性能和功能。
旧 ELK 架构
旧的ELK架构按功能顺序如下:
Logstash:用于日志的收集和处理,支持多种日志格式。Logstash主要负责日志的采集、清洗和格式化。
Elasticsearch:这是一个使用Java开发的分布式搜索引擎,能够解决模糊查询等存在的性能问题。在ELK系统中,Elasticsearch主要用于日志的存储和搜索。
Kibana:Kibana是专门用来与Elasticsearch配合使用的,可以自定义表格对Elasticsearch中的数据进行挖掘分析和可视化。在ELK系统中,Kibana主要用于对Elasticsearch中搜索出来的日志进行可视化展示。
新 ELK 架构
原始ELK架构存在一个问题:Logstash资源占用过高,尤其是在大规模日志采集场景下,Logstash的性能瓶颈较为明显。
为了解决这一问题,Elastic推出了Beats。Beats基于名为libbeat的Go语言框架,包含多个成员,每个成员负责不同的数据采集任务。
Beats 组件
- Filebeat:用于采集日志文件,支持多种日志格式,能够高效地采集和传输日志数据。
- Metricbeat:用于采集服务器的各种指标数据,如CPU、内存、磁盘、网络等,支持多种操作系统和应用程序。
- Packetbeat:用于采集网络数据包,支持多种网络协议,能够分析网络流量和性能。
- Heartbeat:用于监控服务的可用性,通过定期发送心跳包检测服务的健康状态。
- Winlogbeat:用于采集Windows事件日志,支持多种Windows事件日志格式。
- Auditbeat:用于采集系统审计数据,支持Linux和macOS系统的审计日志。
- Functionbeat:用于在无服务器环境中采集数据,支持AWS Lambda等无服务器平台。
- Journalbeat:用于采集Linux系统日志,支持systemd journal日志格式。
Beats采集的数据可以直接发送到Elasticsearch,或者在Logstash进一步处理之后再发送到Elasticsearch。Beats的引入大大扩展了ELK架构的功能,使其不仅限于日志采集,还能支持各种指标和网络数据的采集。
新 ELK 架构的优势
- 资源占用低:Beats组件资源占用较低,适合大规模日志采集场景,减轻了Logstash的负担。
- 功能扩展:Beats组件不仅支持日志采集,还支持各种指标和网络数据的采集,扩展了ELK架构的应用场景。
- 灵活性高:Beats组件可以根据需求选择使用,灵活配置,满足不同场景的监控需求。
新 ELK 架构的工作流程

- 数据采集:Filebeat等Beats组件负责采集日志、指标和网络数据,并将其发送到Logstash或直接发送到Elasticsearch。
- 数据处理:Logstash负责对采集到的数据进行清洗、格式化和处理,然后发送到Elasticsearch。
- 数据存储:Elasticsearch负责存储处理后的数据,并提供高效的搜索和分析功能。
- 数据展示:Kibana负责对Elasticsearch中的数据进行可视化展示,生成仪表盘、图表和报表,帮助用户快速了解系统状态。
通过引入Beats组件,新ELK架构在性能和功能上得到了显著提升,能够更好地满足现代分布式系统的监控需求。
EFK
EFK中的F指的是Fluentd。EFK日志系统架构与原始ELK架构类似,只不过日志的收集和处理角色变成了Fluentd。
Fluentd是一款开源的日志收集器,使用Ruby编写,相较于Logstash更加的轻量化,性能也更加优越,内存占用低。
轻量级日志系统 Loki
ELK(Elasticsearch、Logstash、Kibana)日志系统虽然功能丰富、稳定可靠,但其资源消耗较大,成本较高。对于许多用户来说,ELK的许多功能可能并不常用。因此,Grafana Labs团队开源了Loki,这是一个小巧易用的日志系统,原生支持Grafana,并且特别适合Prometheus和Kubernetes用户。
Loki 架构
Loki的架构非常简单,主要由三个组件组成:
- Loki:主服务器,负责存储日志和处理查询。
- Promtail:代理,负责收集日志并将其发送给Loki。
- Grafana:用于日志数据的可视化展示。
Loki的设计理念类似于Prometheus,但主要为日志服务。Loki特别适合存储Kubernetes Pod日志,能够高效地处理大规模日志数据。
Loki 的优势
- 轻量级:Loki的资源消耗较低,适合中小型企业或对资源敏感的场景。
- 原生支持Grafana:Loki与Grafana无缝集成,提供强大的可视化功能。
- 适合Kubernetes:Loki特别优化了Kubernetes日志的存储和查询,适合云原生环境。
Loki 的工作流程
- 日志采集:Promtail负责从各种数据源(如文件、容器日志等)采集日志数据。
- 日志传输:Promtail将采集到的日志数据发送到Loki服务器。
- 日志存储:Loki将日志数据存储在本地或分布式存储系统中。
- 日志查询:用户通过Grafana查询和分析Loki中的日志数据,生成可视化图表和报表。
ClickHouse + ClickVisual
越来越多的互联网公司开始尝试使用ClickHouse存储日志,以替代传统的Elasticsearch。ClickHouse是一种高性能的OLAP数据库,适合大规模日志数据的存储和查询。相比Elasticsearch,ClickHouse更加节省资源,能够无压力地全量写入日志数据。
ClickHouse 的优势
- 节省资源:ClickHouse的资源消耗较低,适合大规模日志数据的存储。
- 高性能:ClickHouse在处理大规模数据时表现出色,虽然查询性能相比Elasticsearch可能稍慢,但仍能满足大多数需求。
- 灵活性:ClickHouse支持多种数据类型和查询方式,适合不同场景的日志存储需求。
ClickVisual
ClickVisual是一个基于ClickHouse构建的轻量级日志分析和数据可视化平台,由石墨文档开源。ClickVisual提供了日志采集、存储、查询和可视化功能,适合中小型企业使用。
ClickVisual 的改进
尽管ClickVisual在日志存储和分析方面表现出色,但仍存在一些问题,如全文检索效率低、强依赖Kafka等。为了解决这些问题,ClickVisual进行了以下改进:
- 使用Vector替代Kafka引擎:提高了日志摄入的灵活性和稳定性,降低了运维成本,并支持流量控制,避免ClickHouse内存爆满。
- 引入Null表引擎:实现原始日志(从Vector写入的)转换成按照日志解析格式解析之后的真实日志表。
- 支持高效全文检索:在真实日志表中存储原始日志并构建跳数索引,实现了高效的近似全文检索。
ClickHouse + ClickVisual 的工作流程
- 日志采集:使用Vector等工具从各种数据源采集日志数据。
- 日志传输:Vector将采集到的日志数据发送到ClickHouse。
- 日志存储:ClickHouse将日志数据存储在本地或分布式存储系统中。
- 日志查询:用户通过ClickVisual查询和分析ClickHouse中的日志数据,生成可视化图表和报表。
通过引入ClickHouse和ClickVisual,企业可以构建一个高效、灵活且节省资源的日志管理系统,满足不同规模的日志存储和分析需求。