分布式-基础理论&算法
分布式-基础理论&算法
xiaoyan分布式理论
CAP定理:深入理解与应用
简介
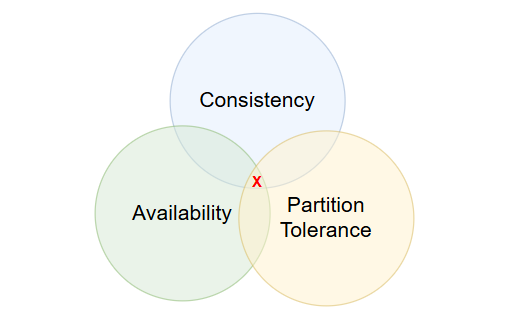
CAP定理,即Consistency(一致性)、Availability(可用性)和Partition Tolerance(分区容错性),是分布式系统设计中的一个基本理论。在计算机科学的分布式系统设计中,CAP定理提供了一个框架来理解系统在面对网络分区时的行为。
- Consistency(一致性):所有节点在同一时间点访问到的数据是一致的。这意味着任何读操作都能读取到最新的写操作结果。
- Availability(可用性):非故障节点在合理的时间内返回合理的响应。这意味着系统即使在部分节点故障的情况下,仍然能够对外提供服务。
- Partition Tolerance(分区容错性):系统在出现网络分区时,仍然能够继续运行。网络分区是指系统中的节点被分割成多个不连通的子集。
架构模型
CAP定理通常被理解为“一个分布式系统最多只能同时满足两个特性”,但实际上存在一个重要的误解:Partition Tolerance(分区容错性)是必须的。因此,实际上只有CP(一致性和分区容错性)和AP(可用性和分区容错性)两种架构模型,而不存在CA(一致性和可用性)架构。
为什么分区容错性是必须的?
在实际的分布式系统中,网络分区是不可避免的。即使网络设计得再好,也无法完全避免网络故障。因此,系统必须能够在网络分区的情况下继续运行,这意味着分区容错性是必须的。
接下来,我们深入了解CP和AP架构模型:
CP(一致性和分区容错性)
CP架构模型保证了系统的一致性和分区容错性。在这种架构下,系统在网络分区时仍然能够保持数据的一致性,但可能会牺牲可用性。例如,在银行系统中,所有节点的数据必须保持一致,即使出现网络分区,系统仍然需要确保数据的一致性。这意味着在数据同步期间,系统可能无法对外提供服务。
应用场景:
- 银行系统:所有交易记录必须保持一致,即使出现网络分区,系统仍然需要确保数据的一致性。
- 分布式数据库:如HBase、MongoDB等,这些系统通常采用CP架构来保证数据的一致性。
AP(可用性和分区容错性)
AP架构模型保证了系统的可用性和分区容错性。在这种架构下,系统在网络分区时仍然能够对外提供服务,但可能会牺牲一致性。例如,在聊天系统中,多个用户可以同时发送消息,但对方收到的消息可能不是最新的,存在一定的不一致性。
应用场景:
- 聊天系统:用户可以随时发送消息,即使消息的顺序可能不完全一致。
- 分布式缓存:如Redis、Memcached等,这些系统通常采用AP架构来保证高可用性。
CAP应用案例
Zookeeper:CP架构
Zookeeper是一个分布式协调服务,广泛用于分布式系统中的配置管理、命名服务、分布式锁等场景。Zookeeper采用CP架构,主要原因如下:
- 强一致性:Zookeeper通过ZAB(Zookeeper Atomic Broadcast)协议来保证数据的一致性。ZAB协议确保所有节点在同一时间点看到的数据是一致的,即使在网络分区的情况下,Zookeeper也会选择牺牲可用性来保证一致性。
- Leader选举:Zookeeper使用Leader选举机制来确保在网络分区时,只有一个Leader节点能够处理写操作。其他节点在Leader选举完成之前无法处理写操作,从而保证了数据的一致性。
Eureka:AP架构
Eureka是一个服务注册与发现系统,用于微服务架构中的服务注册与发现。Eureka采用AP架构,主要原因如下:
- 高可用性:Eureka的设计目标是高可用性。在网络分区的情况下,Eureka仍然能够对外提供服务,即使存在一定的不一致性。Eureka通过多个Eureka Server实例来实现高可用性,每个实例都可以独立处理服务注册与发现请求。
- 最终一致性:Eureka采用最终一致性模型。在网络分区的情况下,不同分区的Eureka Server实例可能会暂时不一致,但随着网络恢复,数据会最终达到一致状态。
Nacos:支持CP和AP架构
Nacos是一个动态服务发现、配置管理和服务管理平台,支持CP和AP架构,主要原因如下:
- Raft协议:Nacos的CP模式基于Raft协议,确保数据的一致性和分区容错性。Raft协议通过Leader选举和日志复制来保证数据的一致性,适用于需要强一致性的场景。
- Distro协议:Nacos的AP模式基于Distro协议,确保系统的高可用性和分区容错性。Distro协议通过数据分片和异步复制来实现高可用性,适用于需要高可用性的场景。
BASE理论:深入解析与应用
简介
BASE理论,即Basically Available(基本可用)、Soft state(软状态)和Eventually Consistent(最终一致性),是对CAP理论的补充和扩展。BASE理论的核心思想是:即使无法做到强一致性,也可以根据每个应用的自身业务特点,采用适当的方式来保证最终一致性。
BASE理论可以理解为CAP理论中AP架构模型的补充。在AP架构中,系统牺牲了一致性来保证可用性,但并不是完全放弃一致性。BASE理论提供了一种在保证系统可用性的同时,逐步实现数据一致性的方法。
详解
Basically Available(基本可用)
基本可用,是指在分布式系统出现故障时,允许损失部分可用性来保证整体系统的基本可用性。
什么叫允许损失部分可用性?
- 响应时间上的损失:比如正常访问时间是0.3秒,但由于系统故障,允许响应时间延长到4秒。这种情况下,系统仍然能够对外提供服务,尽管响应时间有所延长。
- 系统功能上的损失:可以抛弃一些不必要的功能,来保证系统核心功能的可用。例如,在数据访问量巨大时,系统性能有限,可以通过服务降级(关闭不必要的活动)来腾出性能,以供核心业务正常工作。
Soft state(软状态)
软状态,即允许系统中的数据存在中间状态(此时系统数据不一致),但认为该状态并不会影响系统整体的可用性。即系统的数据在不同节点间的数据同步存在延迟。
软状态的应用场景:
- 分布式缓存:在分布式缓存系统中,不同节点的数据副本可能存在短暂的延迟,但系统仍然能够对外提供服务。
- 消息队列:在消息队列系统中,消息的传递可能存在延迟,但系统仍然能够保证消息的最终传递。
Eventually Consistent(最终一致性)
最终一致性,强调的是在系统不同节点中的数据副本,在一段时间后达成完全一致。也就是说,最终一致性可以允许数据不需要实时同步,而是保证最终数据能够达成一致。
最终一致性的实现方法:
- 读时修复:在读取数据的时候,检查数据的不一致,进行修复。例如,在读取数据时,如果发现数据不一致,可以通过读取其他节点的数据来进行修复。
- 写时修复:在写入数据时,检查数据的不一致,进行修复。例如,在写入数据时,如果发现数据不一致,可以通过写入其他节点的数据来进行修复。
- 异步修复:最常用的方式,定时检测数据副本的一致性,进行修复。例如,通过定时任务或事件触发机制,定期检查数据副本的一致性,并进行修复。
分布式算法
Raft算法详解
背景
在当今高度动态的数据中心和应用服务环境中,系统的资源配置需要根据负载情况进行动态调整,以实现资源的高效利用。例如,在双十一期间,电商平台的访问量会大幅增加,而在淡季时,访问量则会显著减少。为了应对这种情况,我们需要能够动态地进行系统扩缩容,即在不影响客户正常使用的情况下,完成配置的升降级,使系统能够自适应地调整资源。
分布式共识算法就是为了应对这些挑战而设计的。Raft算法是Paxos算法的一个具体实现,旨在提供一种易于理解和实现的分布式共识机制。
拜占庭将军问题
为了更好地理解分布式共识算法,我们可以先通过一个经典的例子——拜占庭将军问题来引入。
假设多位拜占庭将军中没有叛军,信使的信息可靠但有可能被暗杀的情况下,将军们如何达成是否要进攻的一致性决定?
解决方案大致可以理解为:先在所有的将军中选出一个大将军,用来做出所有的决定。
举例如下:假如现在一共有3个将军A、B和C,每个将军都有一个随机时间的倒计时器,倒计时一结束,这个将军就把自己当成大将军候选人,然后派信使传递选举投票的信息给将军B和C。如果将军B和C还没有把自己当作候选人(自己的倒计时还没有结束),并且没有把选举票投给其他人,它们就会把票投给将军A。信使回到将军A时,将军A知道自己收到了足够的票数,成为大将军。在有了大将军之后,是否需要进攻就由大将军A决定,然后再派信使通知另外两个将军,自己已经成为了大将军。如果一段时间还没收到将军B和C的回复(信使可能会被暗杀),那就再重派一个信使,直到收到回复。
共识算法
共识是可容错系统中的一个基本问题:即使面对故障,服务器也可以在共享状态上达成一致。
共识算法允许一组节点像一个整体一样进行工作,即使其中的某些节点发生了故障。其正确性来源于复制状态机的性质:一组服务器的状态机计算相同状态的副本,即使部分服务器状态机宕机了,它们依旧能够正常运行。
Raft算法基础
节点类型
在Raft算法中,节点可以分为三种类型:
- Leader(领导者):负责处理所有客户端请求,并将日志条目复制到其他节点。
- Follower(跟随者):被动地接收来自Leader的日志条目,并响应Leader的请求。
- Candidate(候选者):在Leader选举过程中,节点会暂时成为候选者,直到选举出新的Leader。
任期(Term)
Raft算法将时间划分为任意长度的任期(Term),每个任期由一个单调递增的整数表示。任期可以理解为选举周期,每个任期开始时,节点会尝试选举出一个Leader。如果选举成功,Leader将管理整个任期;如果选举失败,任期将结束,新的任期将开始。
日志(Log)
日志是Raft算法中用于存储状态机操作序列的数据结构。每个日志条目包含一个操作指令和一个任期号。Leader负责将日志条目复制到其他节点,并确保所有节点的日志一致。
Leader选举
Leader选举是Raft算法的核心过程之一。当系统启动或当前Leader失效时,节点会进入选举状态,尝试选举出一个新的Leader。
- 选举触发:当一个节点在一段时间内没有收到Leader的心跳消息时,它会认为当前Leader失效,并开始选举过程。
- 投票过程:节点将自己的任期号加1,并转换为候选者状态。然后,它向其他节点发送投票请求。如果一个节点在当前任期内没有投票给其他候选者,并且候选者的日志至少与自己的日志一样新,它就会投票给该候选者。
- 选举结果:如果一个候选者收到了大多数节点的投票,它就成为新的Leader。如果多个候选者同时发起选举,可能会导致选举失败,此时任期将结束,新的任期将开始。
日志复制
日志复制是Raft算法中确保数据一致性的关键过程。Leader负责将客户端请求转换为日志条目,并将这些日志条目复制到其他节点。
- 日志条目添加:Leader接收到客户端请求后,将请求转换为日志条目,并将其添加到自己的日志中。
- 日志条目复制:Leader将新的日志条目发送给所有Follower,并等待大多数Follower确认接收。
- 日志条目提交:一旦大多数Follower确认接收了日志条目,Leader就会将该日志条目标记为已提交,并通知所有节点提交该日志条目。
安全性
Raft算法通过一系列机制确保系统的安全性,包括选举限制、节点崩溃处理和时间与可用性管理。
选举限制
为了防止不一致的节点被选为Leader,Raft算法对选举过程进行了限制:
- 日志匹配:只有日志至少与大多数节点一样新的候选者才能被选为Leader。这样可以确保新Leader的日志是最新的,从而避免数据丢失或不一致。
节点崩溃
Raft算法能够处理节点崩溃的情况,确保系统在部分节点失效时仍然能够正常运行:
- Leader崩溃:如果Leader崩溃,系统会进入选举状态,选举出新的Leader。在此期间,客户端请求可能会被延迟,但系统最终会恢复一致性。
- Follower崩溃:如果Follower崩溃,Leader会继续复制日志条目,并在Follower恢复后继续同步日志。
时间与可用性
Raft算法通过合理的时间管理来确保系统的可用性:
- 心跳超时:Leader定期向Follower发送心跳消息,以维持其领导地位。如果Follower在一段时间内没有收到心跳消息,它会认为Leader失效,并开始选举过程。
- 选举超时:节点在选举过程中会设置一个随机的选举超时时间,以避免多个节点同时发起选举,导致选举失败。
总结
Raft算法通过Leader选举、日志复制和安全性机制,提供了一种易于理解和实现的分布式共识解决方案。Raft算法的核心思想是通过Leader来管理系统的日志复制和状态一致性,确保即使在部分节点失效的情况下,系统仍然能够正常运行。